In my last post I said the mechanics of the design setup were their own post. This is that post.
I’ve held the underlying premise for a long time. A system is only as good as the foundation it sits on. Designs are foundations. Foundations need to be vetted, and they need to suit the situation, because one size never fits all. If the design is wrong, every line of code on top of it inherits the wrongness, and the wrongness compounds.
LLMs landed in the middle of all this. I was building my own formal-design habits at the same time the tools showed up, and I had to figure out how to use them without letting them quietly take the foundation out from under me.
This is what I landed on.
The two things AI is actually good at
There are two things a current LLM is meaningfully better at than I am. It can write fluent documentation, and given an MCP search tool, it can comb the web faster than I can read. Everything else - judgment, trade-off-making, knowing what matters for my team and my company - is something I do better, because the LLM has no idea what my team and my company look like and it never will, fully.
So when I sat down to build a setup, those two abilities became the load-bearing pieces. The LLM does the typing and the searching. I do the deciding.
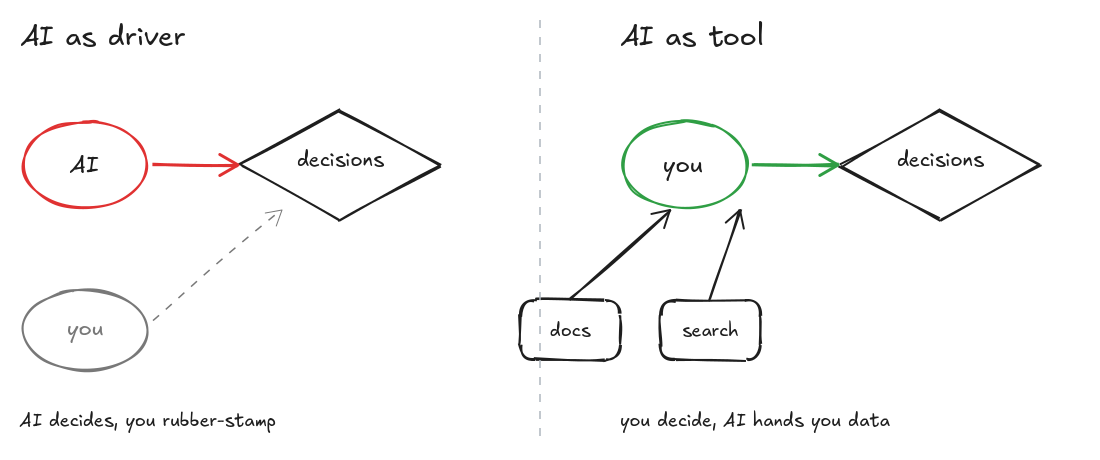
That picture is the version I keep in my head while I’m working. Everything else is scaffolding around it.
What I built
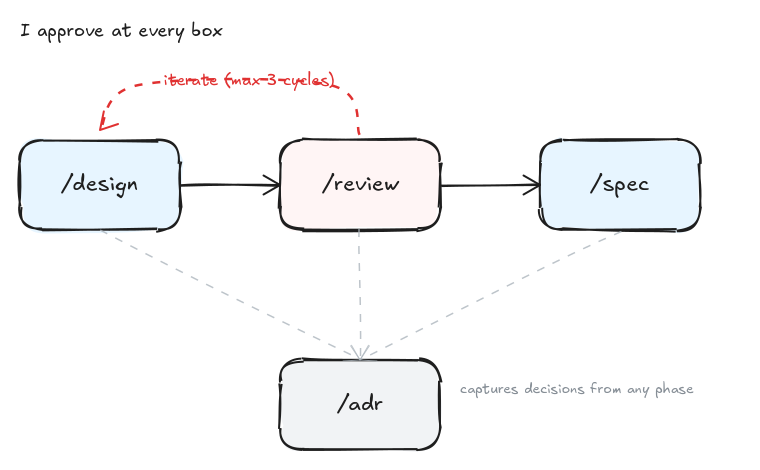
What I ended up with is four skills that chain together. /design, /review, /spec and /adr. Each does one thing and hands off to the next. None of them are autonomous - every one of them stops at a human approval gate before doing anything that matters.
/design produces an architectural design document. It spawns parallel subagents to gather context - memory of past decisions, current codebase patterns, related design docs already written - and then a second wave of parallel Tavily research subagents for prior art, benchmarks and known failure modes. All of that gets synthesized into a single document with the usual sections - problem statement, constraints, quality attribute scenarios, trade-off analysis, capacity estimation, developer ergonomics, migration path.
/review takes that design document and tries to break it. Three subagents on Opus run a cluster of “lenses” against the doc - correctness and security, operations and scale, maintainability and coupling. A devil’s advocate subagent argues against every major decision. A Simplicity Challenger argues for cutting the design down. Output is a review report with critical findings, concerns and a debate log.
/spec turns the design into a behavioral spec - functional requirements, non-functional requirements, acceptance criteria. The thing that gets implementers a contract. WHAT the system does, not HOW it does it.
/adr captures the decisions that came out of all of this in MADR format. The institutional memory for why the choices were made.
The chaining matters. /design has a source-spec mode where it can be driven from an upstream spec. /review has a step that feeds findings back into the spec they came from. /design has an iterate mode to apply review findings to an existing doc rather than rewriting it. The iterate loop is capped at three cycles, on purpose. More on that in a minute.
A quick note on Mem0
Brief detour, because the skills above keep reaching for Mem0 and I haven’t said what it is.
Mem0 is an open-source memory layer for LLM agents. It sits between the model and a vector store (plus optionally a graph store) and gives you a search_memories(query) and add_memory(content) interface that survives across sessions. Internally it extracts facts from whatever you hand it, embeds them, and uses the model itself to decide whether new information should add a memory, update an existing one, delete a stale one or do nothing. With graph mode on, it also captures relationships between entities so you can do multi-hop retrieval - “decisions related to designs in this domain” - in a single query.
In my setup, the skills write structured entries like [Decision] <topic> and [Context] kind=design <slug> at the end of each phase, and search those prefixes at the start of the next one. It’s how the workflow recovers state across a /clear.
/design - parallel context, parallel research
Before /design writes a single line, it fans out parallel subagents - and that’s the expensive part, the part I think makes it actually useful. Three context-gathering subagents in the first phase. One searches Mem0 for prior decisions and ADRs. One greps the codebase for existing patterns and conventions. One scans previously-written design docs for related work. Then three Tavily research subagents - reference architectures, benchmarks and capacity data, post-mortems and known failure modes.
Six parallel research operations before any prose is written. The point is that by the time the skill is generating a design document, it’s working from a synthesis of what’s already been decided here, what the code currently looks like and what the wider industry has done. Not from training data alone.

After the doc is written, two more subagents run a self-critique pass in parallel. One looks for completeness and feasibility issues. The other is the Simplicity Challenger, which I’ll come back to. Both run on Opus, because the failure mode where these run on a weaker model is that they produce shallow generic findings and miss the things that actually matter.
The whole thing stops there and asks me what to do next. It does not auto-advance. It does not call /review for me. It writes a doc, runs critique on it and hands me the result.
/review - hostile by construction
/design is collaborative. /review’s job is to argue against the result.
I built the whole skill around the premise from the prior post. If the LLM is agreeing with me, I asked the wrong question. So /review’s job is not to validate. It’s to find problems. The system prompt is explicit about that - assume defects exist and look for them.
It runs seven lenses across three Opus subagents:
- Correctness and completeness
- Security and data integrity
- Scalability and performance
- Operational readiness
- Cost and resource efficiency
- Developer experience and maintainability
- Coupling and evolutionary architecture

Each lens scores findings as CRITICAL (likely to cause an outage), CONCERN (should be addressed before implementation), OBSERVATION (worth tracking) or CLEAR. Then a devil’s advocate subagent constructs the strongest possible case against every major decision and judges each as “Stands”, “Revise” or “Needs more data”.
For deeper passes, a Full review adds three more persona subagents. The Pessimist constructs the worst-case cascading failure. The Newcomer tries to write onboarding docs from the design and reports where they got stuck. The Operator writes a runbook skeleton and finds the gaps. Each one is built to surface a different class of problem - blast radius, comprehensibility, debuggability - that the lens analysis tends to miss.
The output is a review report with explicit verdicts. I read it. I push back on findings I disagree with. The skill doesn’t get to win - if I think a CRITICAL is wrong because it’s missing context the LLM doesn’t have, I say so and we move on.
What happens between iterate cycles is the part of this loop I had to learn to do well. /design iterate on its own is mechanical. It takes the review findings and patches the holes the lenses found. The output is a design with fewer holes but no new substance. So I treat the iterate step as the moment I sit down with the doc myself and inject opinion. Where do I want this to go that the lenses didn’t push on? Which trade-off am I willing to take that the LLM hasn’t weighed? What context am I holding that should shape the next pass? By the time I hand the updated doc back to /review, it’s a meaningfully different document with enough new material to warrant a fresh adversarial pass. Without that step, the second review tends to come back saying “looks better, ship it” because the LLM is mostly reading its own corrections.
This is where the cycle cap kicks in. /design and /review can ping-pong indefinitely if you let them. I capped both at three cycles, and at the cap the skill stops and asks me explicitly - ship what we have, accept the remaining risks (which generates an ADR documenting the acceptance) or run a re-check on outstanding criticals. I didn’t cap it because of token cost. I capped it because an infinite design loop is a way of avoiding the decision, not improving it.
The Simplicity Challenger
This one came from pain.
Opus is an impressive model, and the more context you feed it the more interesting its output gets, but its sense of “good design” is calibrated against an internet’s worth of writing by and for big tech companies. Throw it a problem and its first instinct is to reach for the patterns that sit in Netflix architecture blog posts. Event bus, queue and worker pool, read replicas, occasionally a sidecar or CQRS.
Some of those patterns are right for some problems. Most of them are wrong for mine. I work at a 15-person IT shop. Our business uses our systems, but not at internet scale. The simpler design is almost always the right design, because the simpler design is the one a small team can actually maintain, and because the edge cases the complicated patterns solve are edge cases we will not see.
The first few times I ran the design skill I watched it cheerfully suggest architectures that would have eaten half a developer-year just to keep running. Not because it was wrong about what the architecture would do. Because it had no concept of what we could afford to run.
So I added a Simplicity Challenger subagent to the self-critique step. Its only mandate is to argue for reduction. It reads the design and is required to name specific components or patterns that add complexity without a clearly stated quality attribute requirement, and to propose a simpler alternative that satisfies at least 80% of the stated requirements. Then it issues a verdict - “proportional”, “incidental” or “over-engineered” - and if it picks one of the last two, it has to name the parts.
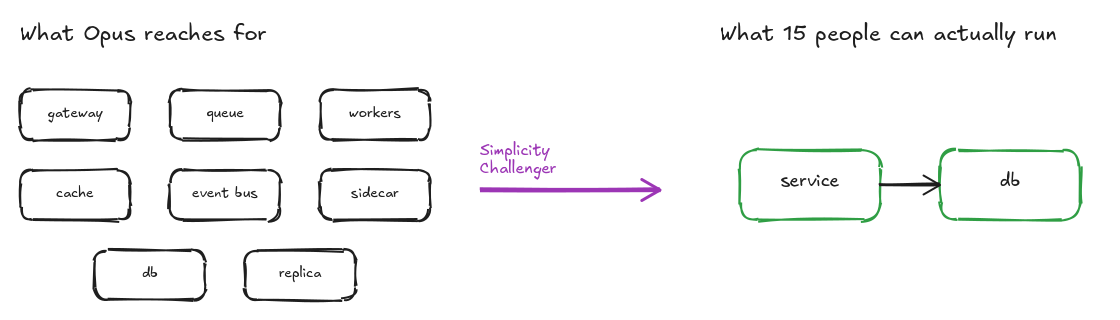
I do not let it cut things by default. I read what it proposes and I decide. Roughly half the time it’s right, in my experience. The other half it’s pulling out something the design genuinely needs and I push back. That ratio is fine - when it’s right it saves me from running a system I can’t operate, and when it’s wrong it still forces me to articulate why I’m keeping something I’d have kept anyway.
The lesson generalizes. The default LLM is not calibrated to your situation. If you have a constraint that isn’t in the training data - team size, budget shape, regulatory weirdness, vendor restrictions - it will quietly violate that constraint unless you build something explicit to defend against it.
/spec - what not how
/spec is briefer. After a design clears review, /spec turns it into a contract for whoever has to implement it. Functional requirements get numbered IDs. Non-functional requirements get measurable criteria. Acceptance criteria are written in given/when/then form so a test can be derived directly from them.
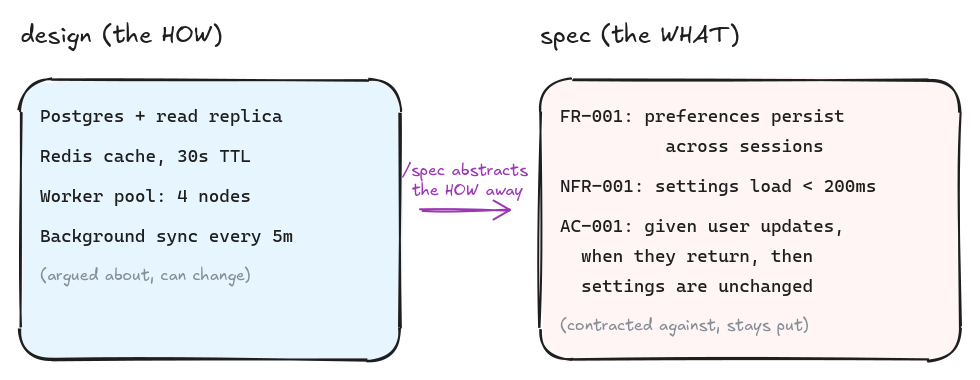
The single rule I care most about here is the WHAT/HOW split. A spec says “the system shall persist user notification preferences across sessions”. It does not say “use Redis”. The HOW belongs in the design, where it can be argued about. The WHAT belongs in the spec, where it gets contracted against.
When the design changes the HOW, the spec doesn’t move. When requirements change the WHAT, the design might have to move. That asymmetry is the whole reason these are separate artifacts.
/adr - the why layer
ADRs are the thing I would have wanted most when I walked into this role two years ago, before I knew they had a name. They are the record of why a decision was made, written at the moment it was made, by the person who made it. Not a meeting summary. Not a wiki page that grows stale. A versioned document that captures the options considered, the constraints in play, the choice and the consequences.
/adr is the simplest of the four skills. It searches Mem0 for related prior decisions, asks whether to use the full MADR template or the minimal one and writes the doc. For decisions with three or more options it spawns one Tavily subagent per option to research them in parallel. Then it asks me to confirm the framing, the options and the chosen outcome before writing anything.
The other skills mostly suggest creating an ADR rather than creating one themselves. When /review finds a decision worth recording. When /design makes a non-obvious trade-off. When I accept risk past the iteration cap. All of those route through /adr only after I confirm.
Put together, the four skills choreograph like this. You can enter from either side - a fresh design, or an existing spec - and either route lands you in the same review loop.

What this isn’t doing for me
The thing I want to be clearest about is that nothing in this pipeline makes a decision. Every skill stops and asks. /design writes a doc and asks what I want to do next. /review writes a report and asks how I want to address the findings. /spec asks about scope and audience before it writes anything. /adr asks me to confirm the framing.
I approve at every box on the diagram up there. I read every output. I argue back when it’s wrong. The LLM is doing the documentation - which it’s good at - and the search - which it’s good at - and it’s surfacing problems and counter-arguments I might have missed. It is not deciding what the foundation should look like. That part is mine, and it stays mine.
This matters more than the architecture of the skills themselves. The thing that has gone wrong every time I’ve watched an LLM-built system fall over is that someone handed it judgment somewhere along the way. Whatever the skill, whatever the prompt, whatever the framework, if the person at the keyboard isn’t reading the output and pushing back on it, the output drifts. Slowly at first, then quickly, and then you’re operating a system you don’t understand.
The pipeline is scaffolding around the fact that I am still the architect. The LLM is good help, not a replacement.
What I’m not covering here
There are pieces of the setup I’m leaving for other posts. The Tavily research notes that get appended to each design doc as a cached appendix so reviews don’t refetch what designs already gathered. The handoff into /build-init once a spec is ready to be implemented. The cycle-tracking machinery that holds it all together.
Where I am going next
Mem0 is the piece of this setup I’m least confident in.
On paper it’s the obvious answer. A persistent memory graph that survives across /clears, links decisions to designs to specs, builds a queryable record of why everything is the way it is. The skills lean on it heavily - every one of them does a Mem0 search at the start of Phase 1, every one of them writes back a structured entry at the end.
In practice I’m having a hard time pointing at the value. The overhead to maintain a memory graph across all the projects I run is real, and as more projects get added the linkages get patchy - sometimes the edges work, sometimes they don’t and I can’t always tell why before I’m in the middle of a flow and need the answer. The vectorization step is also a smidge heavier than I expected. There are moments in a /design Phase 1 where I’m just watching it embed things and waiting, when what I actually want is the next question.
Schema lock-in is the other concern. I tried to design the prefix shapes so the graph could evolve over time - [Decision], [Context] kind=design, all of that - but if I change my mind about what the graph should look like, migrating the entries already in it is not a trivial exercise. The migration itself is exactly the kind of project I would not want to pick up.
What I’m thinking now is that for my scale of work an LLM can pull most of the same job off with the right workflow documents kept current on disk. A REGISTRY.md that records which spec is active and where each one sits in its cycle does most of the cross-session work Mem0 was doing for me. The skills already maintain that file, the cycle counts already live in Last Action columns, and the juicy data - architectural decisions, scope decisions, accepted risks - already lives in numbered ADRs that any skill can read.
So next, I’m dropping Mem0. The skills will lose their prefix-registry lookups and lean on the documents the workflow already produces. There will be a cost somewhere - I’m not naive about that - but I’d rather pay a known cost in flatter context than an unknown one in a graph I can’t reshape.
For now - argue with it in design, direct it in implementation, don’t hand it your judgment in either one. And when it tries to talk you into a system three sizes too large for the team that has to run it, send in something with a mandate to argue back.
I do expect that I am going to continue finding things I like and do not like about this process - I’ll share any big findings that I make.